大语言模型(LLM)要想给出可信答案,必须随时访问到“知识”和“工具”。过去一年里,最常见的做法是把文档做成向量并存入向量数据库,通过 RAG(Retrieval-Augmented Generation)管道检索后再交给模型。然而 2024 年底,Anthropic 主导推出的 MCP(Model Context Protocol) 迅速走红,为模型调用外部数据和指令带来了新的范式。本文将拆解 MCP 协议与传统向量数据库检索的核心原理、差异及协同用法,并给出适用场景建议。
一、什么是 MCP 协议?
MCP 是一种开放标准,为 AI 应用与外部数据源 / 工具之间建立双向、高一致性的通信通道。开发者只需实现一次 MCP 客户端或服务器,就能让模型在运行时动态发现并调用数十种数据源(SQL、NoSQL、向量库、HTTP API 乃至 IoT 设备),从而把“ M×N 集成难题”化成“ M+N”【MCP 将 AI 应用接入复杂工具变成统一接口】。
协议层面,MCP 定义了:
- 资源(resource):只读数据,如数据库查询结果、文件摘要等。
- 工具(tool):带副作用的动作,如写入记录、发送通知、执行脚本。
- 双向流式上下文:模型收到数据后还能继续调用工具,实现 Agentic 工作流。
二、什么是向量数据库检索?
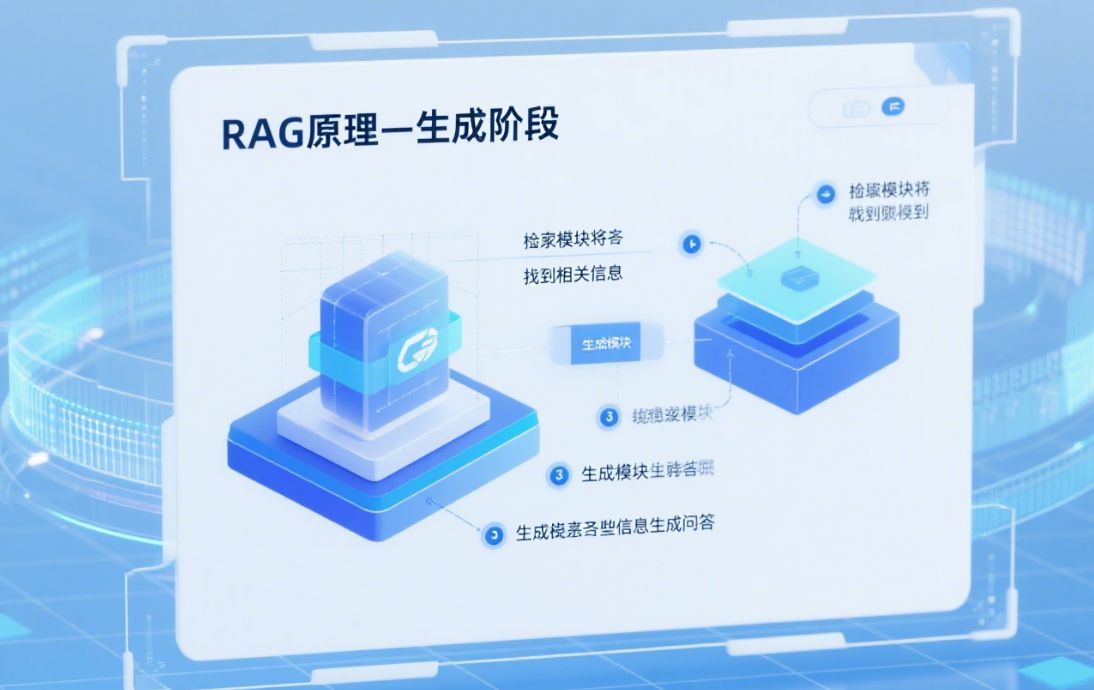
向量数据库把文本、图像、音频等非结构化内容嵌入成高维向量,并构建近似最近邻(ANN)索引。当用户提出问题时,系统先计算查询向量,再到数据库里找“最接近”的向量片段,把对应原文当作上下文喂给 LLM。它解决了传统关键字搜索“只能匹配字面”的痛点,已广泛用于聊天知识库、推荐系统与多模态检索【向量检索用嵌入实现语义匹配】。
三、五大核心差异
- 抽象层级MCP 关注“怎么连”;向量检索 关注“怎么查”。前者是接口 / 协议,后者是存储 / 索引。
- 数据准备方式向量检索 需要先做文本切分、Embedding、建 ANN 索引;MCP 可以直接暴露现有结构化或非结构化数据,零预处理即可查询。
- 查询语义向量库返回“相似度最高的 top-k 片段”;MCP 资源可以返回精确 SQL 结果、枚举值或文件内容,还允许工具型调用产生副作用。
- 实时性与成本在线嵌入 + 相似度搜索会带来额外延迟与 GPU 费用;MCP 可以甚至跳过嵌入,直接读取最新业务数据,实现毫秒级并保持一致性。
- 可操作性向量检索多数是只读;MCP 的工具模式天生支持写操作,使 Agent 能“查-思-写”闭环,例如删除工单或更新库存。
四、典型适用场景对比
| 需求场景 | 更适合 MCP | 更适合向量检索 |
|---|---|---|
| 实时库存、订单、用户画像 | ✅ | |
| FAQ、手册、长文档问答 | ✅ | |
| 多步骤 Agent 执行(查+改) | ✅ | |
| 模棱两可、模糊语义搜索 | ✅ | |
| 快速集成多种数据源 | ✅ |
五、协同使用:RAG 2.0 的混合检索范式
在企业落地中,两者并非二选一。常见做法是:
- 结构化查询走 MCP:将 ERP / CRM 等表格暴露为 MCP 资源,低延迟返回权威数据。
- 非结构化语义走向量库:知识库仍用 Pinecone、Milvus 等;MCP Server 内部再调用向量数据库 SDK。
- 模型侧统一消费:LLM 只需要一个 MCP 客户端,就能无差别获得两种结果,再用自适应 RAG 或 Re-Rank 选最佳上下文。
六、未来趋势
- 标准化 & 开源生态:Block、Cloudflare、Apollo 等公司已贡献数十个 MCP 连接器,向量库厂商也在原生支持 MCP Server。
- Hybrid Retrieval:向量 + 关键词 + 结构化查询在统一框架下融合排序,进一步提升答案相关度与解释性。
- Agentic AI:工具调用与上下文检索共存,推动 LLM 从“会聊天”升级为“会行动”。
纵观演进,MCP 提供的是“统一总线”,向量数据库提供的是“高维感知”。理解并结合两者,才能构建既实时又有深度记忆的下一代 AI 应用。