在大语言模型(LLM)快速迭代的当下,支持百万级甚至更长 token 的上下文窗口已成为行业热点。然而,随之而来的成本飙升、推理延迟与信息稀释问题也让人望而却步。另一条备受关注的路径,是自 2024 年底由 Anthropic 等厂商推动的 MCP(Model Context Protocol)。MCP 通过“协议+工具链”方式,将对话上下文拆分并在本地或远程持续存储,看似能绕开超长窗口的硬件瓶颈。二者究竟是替代还是互补?本文拆解核心技术与应用场景,为开发者与产品经理给出决策参考。
一、超长上下文窗口:优势与痛点并存
- 天然的“一包流”体验单轮请求即可塞入完整文档、长代码库或上万轮对话,极易在 PoC 阶段交付可用 Demo。
- 技术与成本门槛陡增
- 需要更大的显存或分布式推理;
- 推理延迟与资源调度复杂度呈阶梯式上升;
- Token 越多,注意力稀释越严重,令重要信息被噪声淹没。
- 维护难点客户端需将全部历史反复上传,带宽与安全合规压力显著提升。
二、MCP 协议:用“记忆系统”打补丁
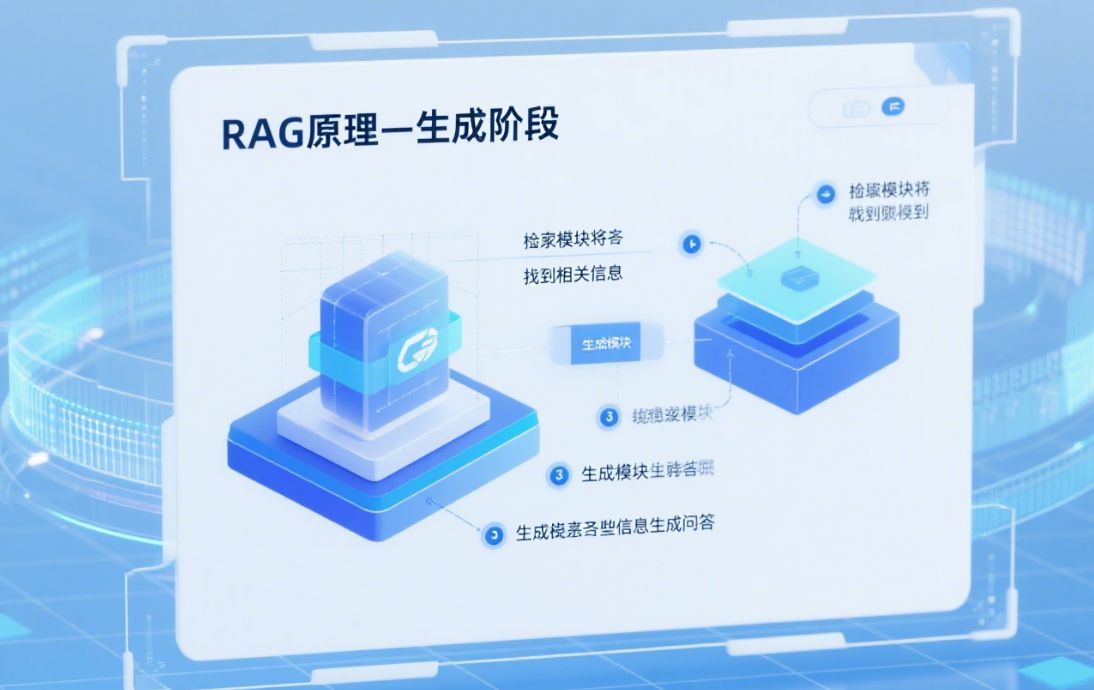
- 协议定位MCP 类似“AI 世界的 HTTP”——定义 LLM 与外部数据源/工具的通用接口,使应用可按需“拉取”所需片段,而非一次性压进提示词中。
- 分层记忆架构
- 短期记忆:采用滑动窗口缓存最近 N 轮上下文;
- 长期记忆:通过向量数据库(FAISS 等)储存摘要与关键实体;
- 环境上下文:设备状态、时间、地理等元数据随用随取。
- 动态优先级调度MCP 客户端可结合 TF-IDF、位置熵等算法实时重分配注意力,降低冗余计算约 30%–40%。
- 工具生态目前已有开源 MCP 服务器、LangChain MCP 模块、IDE 插件等,开发者无需自研连接器即可挂载文件系统、数据库、Git、CRM 等多源数据。
三、MCP 能否彻底“替代”超长窗口?核心对比
| 维度 | 超长上下文窗口 | MCP 协议 |
|---|---|---|
| 一次性容量 | 动辄 1M+ tokens,最直观 | 受限于临时窗口(数千 tokens),但可分批检索 |
| 推理速度 | 随窗口长度线性~二次增长 | 先检索后推理,总体更可控 |
| 部署成本 | 高端 GPU、分布式跨节点通信 | 向量库+通用存储,可跑在普通云主机 |
| 精度稳定性 | 上下文稀释,容易“跑偏” | 召回策略决定质量,需要良好 RAG 设计 |
| 安全合规 | 敏感数据反复上传,治理困难 | 私有 MCP 服务器可实现数据不出本地 |
| 开发复杂度 | Prompt 工程简单 | 需搭配 RAG、Embedding、缓存管理 |
结论:MCP 并非简单替代,而是“解耦+增量”的思路:在同等预算下,MCP 更容易落地企业私有化场景;对需要强一致、低延迟的即时对话,适度的长窗口加上 MCP 记忆层是当下折中方案。
四、典型应用场景与落地建议
- 智能客服 / Copilot
- 实施:短期窗口保持对话流畅,长期记忆追踪用户画像、订单等。
- 收益:用户满意度可提升 20–30%,GPU 消耗下降约 40%。
- 代码生成 / IDE 插件
- 实施:IDE 中的 MCP 服务器暴露项目文件树;模型按需读取函数定义,避免一次性注入大量代码。
- 收益:平均响应时间缩短 35%,错漏率显著降低。
- 法规/合规文档分析
- 实施:将法律条款向量化入库,通过关键词+语义检索分批提供给模型。
- 收益:关键条款召回率可达 90% 以上,而显存成本保持稳定。
五、开发者实战指南
- 混合策略优先:小-中等窗⼝(8K–32K)+ MCP 检索,兼顾即时上下文与长期一致性。
- Chunk 策略:控⼿别把段落切得过碎,一般 200–500 tokens/块利于检索召回。
- 持续评估 Recall vs. Latency:每季度复审知识库过期内容,动态调整 Embedding 与索引。
- 关注社区生态:Claude Desktop、Cursor IDE、Logto 等已内建 MCP 支持,快速验证 POC。
超长上下文窗口与 MCP 协议分别从“硬扩容”和“软分流”两端解决 LLM 记忆难题。未来,当硬件与稀释算法进一步突破,窗口长度仍会持续增长;但在可预见的落地周期里,MCP 通过协议化、分层记忆与生态整合所带来的开发敏捷与合规优势,注定成为企业级 AI 系统的“默认选项”。真正的生产级应用,多半将以二者的协同形态存在——长窗口承载即时逻辑连贯,MCP 负责持久记忆与工具互操作,共同驱动“无限上下文”体验加速到来。