MCP 协议通过以下几个关键机制,为大型语言模型(LLM)在运行时动态地注入、管理和维护上下文信息:
- 标准化的消息格式与函数调用 MCP 基于 JSON-RPC 2.0 规范,定义了一套统一的消息结构,包含“请求(request)”、“响应(response)”和“通知(notification)”三种类型。每次模型需要外部上下文时,MCP 客户端会向 MCP 服务器发送一个 JSON-RPC 请求,其中载明所需工具(tool)的名称、参数结构和调用意图,服务器执行相应操作后将结果以 JSON-RPC 响应的形式返回,模型即可将这些结果直接并入对话上下文中进行推理或生成。
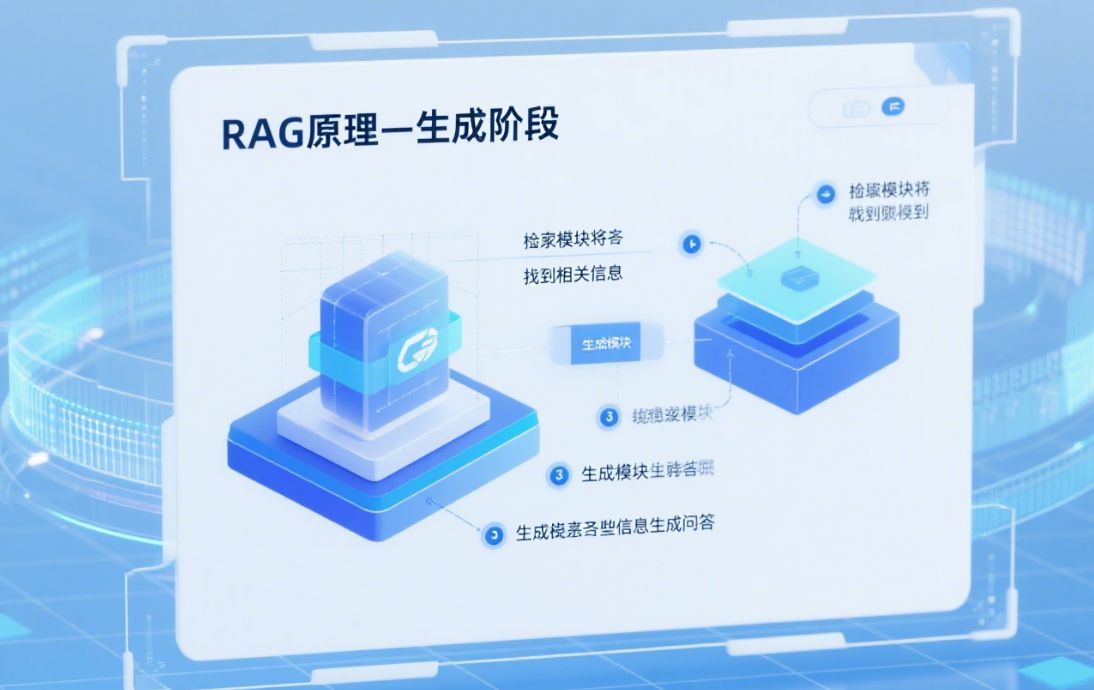
- 工具(Tool)描述与能力协商 在会话初始阶段,MCP 客户端会向服务器或模型自身声明可用的“工具”列表,包括每个工具的名称、功能描述、接收参数的 JSON Schema 以及预期的返回格式。这种能力协商机制使得模型能够“看到”所有可用工具及其使用方式,并在逻辑中选择最合适的工具来检索或操作外部数据。
- 状态化连接与上下文持续性 与一次性请求—响应不同,MCP 支持状态化连接(stateful connection),允许在同一会话中多次发起请求并保留历史状态。模型在后续调用中可以沿用之前的工具调用记录、参数和返回结果,从而实现跨轮对话的上下文持续性。这一特性对于多步骤任务尤其关键,比如先查询数据库、再处理结果、最后汇总报告。
- 上下文元数据与标签 MCP 协议在每条消息中都可以附带“上下文元数据”(contextual metadata),例如请求发起时间、用户身份标识、操作权限等字段,服务器与模型能够据此判断当前环境、审计调用权限并为后续推理提供更多信息维度。元数据的标准化标签(metadata tagging)机制,还能让模型在生成输出时自动引用来源、注明数据时效或进行错误处理。
- 双向交互与异步通知 MCP 不仅支持模型主动调用工具,同时也允许服务器通过“通知(notification)”的形式向模型推送新上下文(如实时事件、数据变更)。这种双向交互能力保证了 LLM 在处理需要高度时效性的信息时,能够及时获得更新,而不必等待下一个主动请求。
- 可扩展性与跨平台兼容 MCP 提供官方 SDK(如 Python、TypeScript、Java、C# 等语言),并定义了开放的扩展点,让开发者可自定义工具、配置专用的 MCP 服务器来接入内部系统或第三方服务。无论是在云端部署的微服务,还是在本地运行的应用,模型都能通过同一套 MCP 接口无缝获取所需上下文。
通过上述机制,MCP 将“外部数据源”、“工具函数”与“对话历史”三者统一在同一个标准化的协议层中,使大型语言模型能够在运行时按需调用、动态组合和持续维护上下文,从而显著提升模型在复杂、多步骤和跨域任务中的准确性与可靠性。