什么是模型幻觉?AI大模型“说错话”的原因与解决方案全解析
在使用大语言模型(如ChatGPT、Claude、Gemini)时,用户经常会遇到AI“自信却错误地回答”的情况。这种现象被称为“模型幻觉(AI Hallucination)”,是当前AI应用中一个重要且尚未完全解决的问题。
一、什么是模型幻觉?
“模型幻觉”指的是AI语言模型在缺乏真实信息支撑的情况下,生成虚假的或不准确的内容,并且语气上非常自信,使用户难以辨别真假。其形式包括:
- 虚构事实:如捏造人物、历史事件、公司信息;
- 编造引用:伪造不存在的论文、书籍、网页来源;
- 错误推理:逻辑链条正确但基础数据错误;
- 胡乱联想:将多个不相关概念强行关联;
示例:用户询问“图灵获得过哪些奖项?”模型可能编造出“图灵获得诺贝尔奖”,而事实上图灵并未获得诺贝尔奖。
二、为什么大模型会产生幻觉?
- 预测驱动机制语言模型基于上下文预测下一个最可能的词,而非真实记忆或检索事实,因此更倾向于“流畅地胡说”。
- 训练数据缺陷模型训练数据中存在错误信息或未涵盖的领域,容易造成内容生成“填空式发挥”。
- 无事实验证模块传统语言模型本身并不具备事实验证机制,无法判断自己说的是否真实。
- 提示词不明确用户的问题本身模糊,容易让模型过度推测甚至“想象答案”。
三、模型幻觉的风险
- 误导用户:特别是在医学、法律、金融等专业领域,错误信息可能造成严重后果;
- 破坏信任:频繁出现幻觉会降低用户对AI系统的信任;
- 数据污染:AI生成内容被其他AI继续学习,会放大错误形成“幻觉闭环”。
四、主流解决方案与实践方法
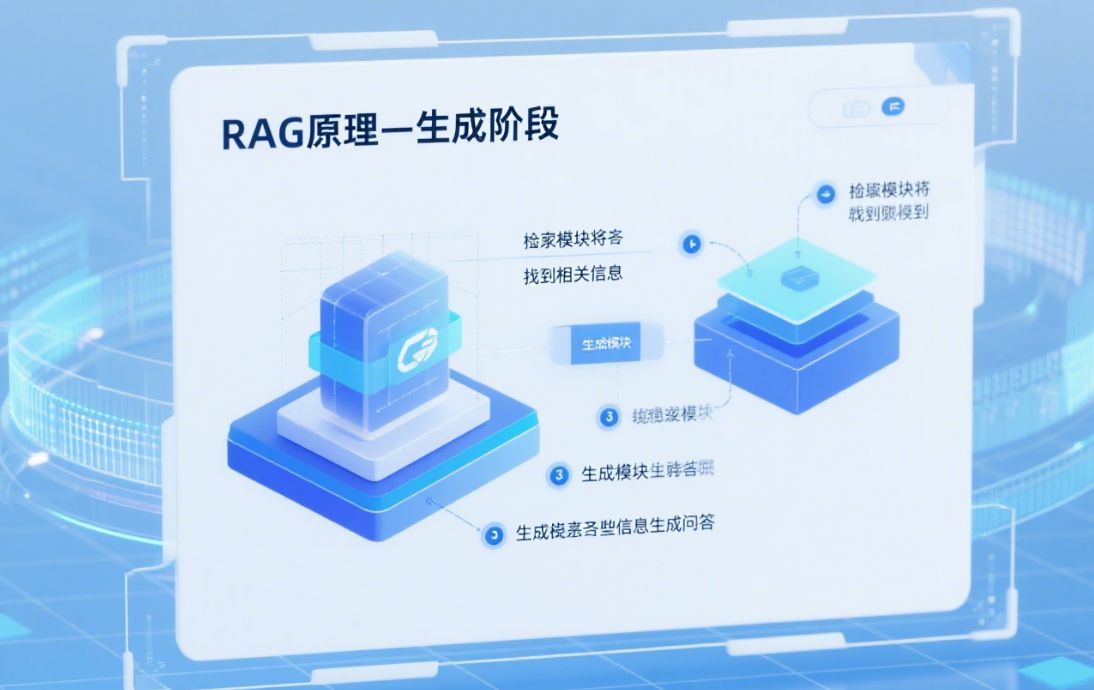
- RAG(检索增强生成)机制结合外部数据库、文档或搜索引擎进行事实核查,模型不再“凭空想象”,而是“依据材料生成”。
- 多模型验证利用多个模型对生成内容交叉审查,提高正确率。
- 加入事实检测器在输出内容后增加“验证层”,检测输出是否符合事实逻辑与数据库资料。
- 微调训练数据对特定场景(如医疗、法律)进行高质量数据微调,减少开放性幻想空间。
- 优化提示词(Prompt)设计使用更具体、更限制性的提示词,例如“根据2023年官方数据,列出前五大GDP国家”。
- **让模型“说出来源”**要求模型标注回答依据或引文链接,用户可进一步查证。
五、总结
模型幻觉是当前AI技术不可忽视的问题,但它并非无法规避。通过结构化检索(RAG)、明确提问、事实验证机制以及技术优化,我们正逐步构建一个“更可靠、更可信”的AI生成生态。在AI成为生产力工具的同时,理解其局限、合理使用,尤为重要。