什么是大模型上下文工程?
大模型上下文工程(Context Engineering)是指在调用大型预训练模型(如 GPT、Gemini、Claude 等)时,通过精细构建和管理输入文本的上下文信息,以最大化模型理解能力和输出质量的一系列方法和实践。
上下文工程的核心要素
- 上下文窗口管理在限定的 token 长度内合理组织信息,包括核心指令、示例、背景资料以及必要的元数据,确保模型能够“看到”并正确关联所有关键信息。
- 段落与格式分块将长文本分成逻辑段落或标记块,比如用标题、编号、代码框等结构化形式呈现,让模型更容易捕捉层次与重点。
- 依赖链提示对于涉及多步推理或复杂流程的任务,通过在上下文中明确列出步骤、变量关系和前置条件,引导模型按预期顺序执行推理。
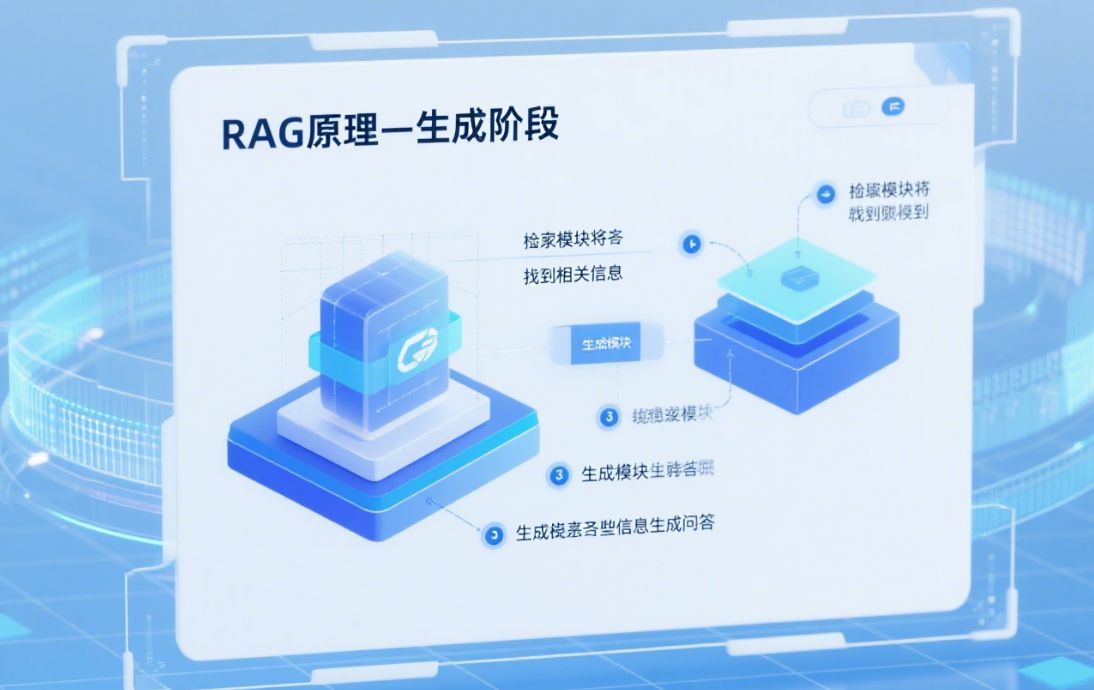
- 动态上下文扩展在多轮对话或多阶段生成场景中,用技术手段(如内存管理、检索增强)持续注入新信息或检索历史片段,保持长上下文一致性。
- 上下文压缩与摘要当原始上下文过长时,先让模型或工具对信息进行自动摘要,取出关键信息,再将摘要结果用于后续提示,降低 token 消耗并提高相关性。
典型应用场景
- 复杂文档问答:在法律合同、学术论文等长文档场景中,先通过检索或分块摘要形成重点上下文,再回答用户提问。
- 多轮对话系统:通过对话状态管理和关键对话历史提取,让模型在长对话中保持上下文连贯性;
- 代码生成与调试:将项目文件结构、函数签名与示例输入一起组织成上下文,使模型生成或修复代码时能够对全局有清晰认识;
- 决策支持与流程自动化:在商业策略、科研实验等多步骤流程中,将决策节点和依赖信息嵌入上下文,确保模型按预定流程给出建议或输出。
掌握上下文工程,可以让大模型在各种复杂场景中发挥最佳性能,减少信息丢失和误解,显著提升生成结果的准确性和一致性。